publications
Publications by categories in reversed chronological order.
-
 Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt EnsemblesInternational Conference on Computer Vision, Oct 2025
Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt EnsemblesInternational Conference on Computer Vision, Oct 2025Multimodal large language models (MLLMs) are increasingly used to evaluate text-to-image (TTI) generation systems, providing automated judgments based on visual and textual context. However, these "judge" models often suffer from biases, overconfidence, and inconsistent performance across diverse image domains. While prompt ensembling has shown promise for mitigating these issues in unimodal, text-only settings, our experiments reveal that standard ensembling methods fail to generalize effectively for TTI tasks. To address these limitations, we propose a new multimodal-aware method called Multimodal Mixture-of-Bayesian Prompt Ensembles (MMB). Our method uses a Bayesian prompt ensemble approach augmented by image clustering, allowing the judge to dynamically assign prompt weights based on the visual characteristics of each sample. We show that MMB improves accuracy in pairwise preference judgments and greatly enhances calibration, making it easier to gauge the judge’s true uncertainty. In evaluations on two TTI benchmarks, HPSv2 and MJBench, MMB outperforms existing baselines in alignment with human annotations and calibration across varied image content. Our findings highlight the importance of multimodal-specific strategies for judge calibration and suggest a promising path forward for reliable large-scale TTI evaluation.
@article{slyman2025judge, author = {Slyman, Eric and Tanjim, Mehrab and Kafle, Kushal and Lee, Stefan}, title = {Calibrating MLLM-as-a-judge via Multimodal Bayesian Prompt Ensembles}, journal = {International Conference on Computer Vision}, month = oct, year = {2025}, } -
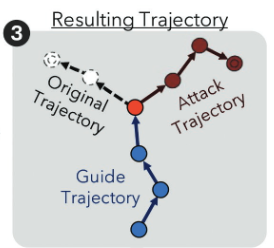 Hijacking Vision-and-language Navigation Agents with Adversarial Environmental AttacksWinter Conference on Applications of Computer Vision, Feb 2025
Hijacking Vision-and-language Navigation Agents with Adversarial Environmental AttacksWinter Conference on Applications of Computer Vision, Feb 2025Assistive embodied agents that can be instructed in natural language to perform tasks in open-world environments have the potential to significantly impact labor tasks like manufacturing or in-home care – benefiting the lives of those who come to depend on them. In this work, we consider how this benefit might be hijacked by local modifications in the appearance of the agent’s operating environment. Specifically, we take the popular Vision-and-Language Navigation (VLN) task as a representative setting and develop a whitebox adversarial attack that optimizes a 3D attack object’s appearance to induce desired behaviors in pretrained VLN agents that observe it in the environment. We demonstrate that the proposed attack can cause VLN agents to ignore their instructions and execute alternative actions after encountering the attack object – even for instructions and agent paths not considered when optimizing the attack. For these novel settings, we find our attacks can induce early-termination behaviors or divert an agent along an attacker-defined multi-step trajectory. Under both conditions, environmental attacks significantly reduce agent capabilities to successfully follow user instructions.
@article{yang2025hijacking, author = {Yang, Zijiao and Shi, Xiangxi and Slyman, Eric and Lee, Stefan}, title = {Hijacking Vision-and-language Navigation Agents with Adversarial Environmental Attacks}, journal = {Winter Conference on Applications of Computer Vision}, month = feb, year = {2025}, } -
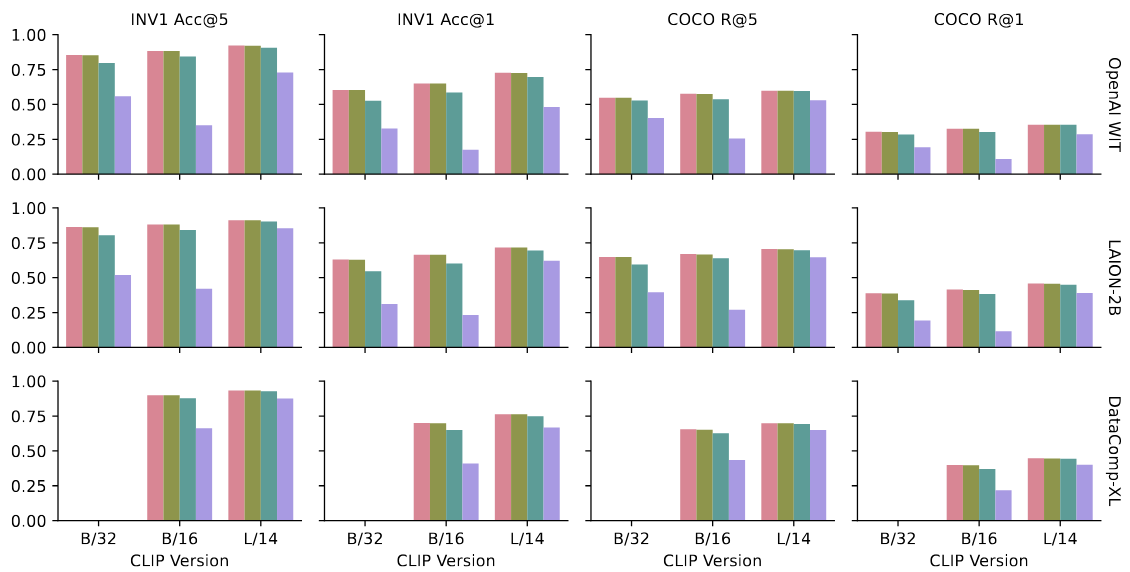 You Never Know: Quantization Induces Inconsistent Biases in Vision-Language Foundation ModelsNeurIPS Workshop on Responsibiliy Building the Next Generation of Multimodal Foundation Models, Dec 2024
You Never Know: Quantization Induces Inconsistent Biases in Vision-Language Foundation ModelsNeurIPS Workshop on Responsibiliy Building the Next Generation of Multimodal Foundation Models, Dec 2024We study the impact of a standard practice in compressing foundation vision-language models-quantization-on the models’ ability to produce socially-fair outputs. In contrast to prior findings with unimodal models that compression consistently amplifies social biases, our extensive evaluation of four quantization settings across three datasets and three CLIP variants yields a surprising result: while individual models demonstrate bias, we find \emphno consistent change in bias magnitude or direction across a population of compressed models due to quantization.
@article{slyman2024quantization, author = {Slyman, Eric and Kanneganti, Anirudh and Hong, Sanghyun and Lee, Stefan}, title = {You Never Know: Quantization Induces Inconsistent Biases in Vision-Language Foundation Models}, journal = {NeurIPS Workshop on Responsibiliy Building the Next Generation of Multimodal Foundation Models}, month = dec, year = {2024}, } -
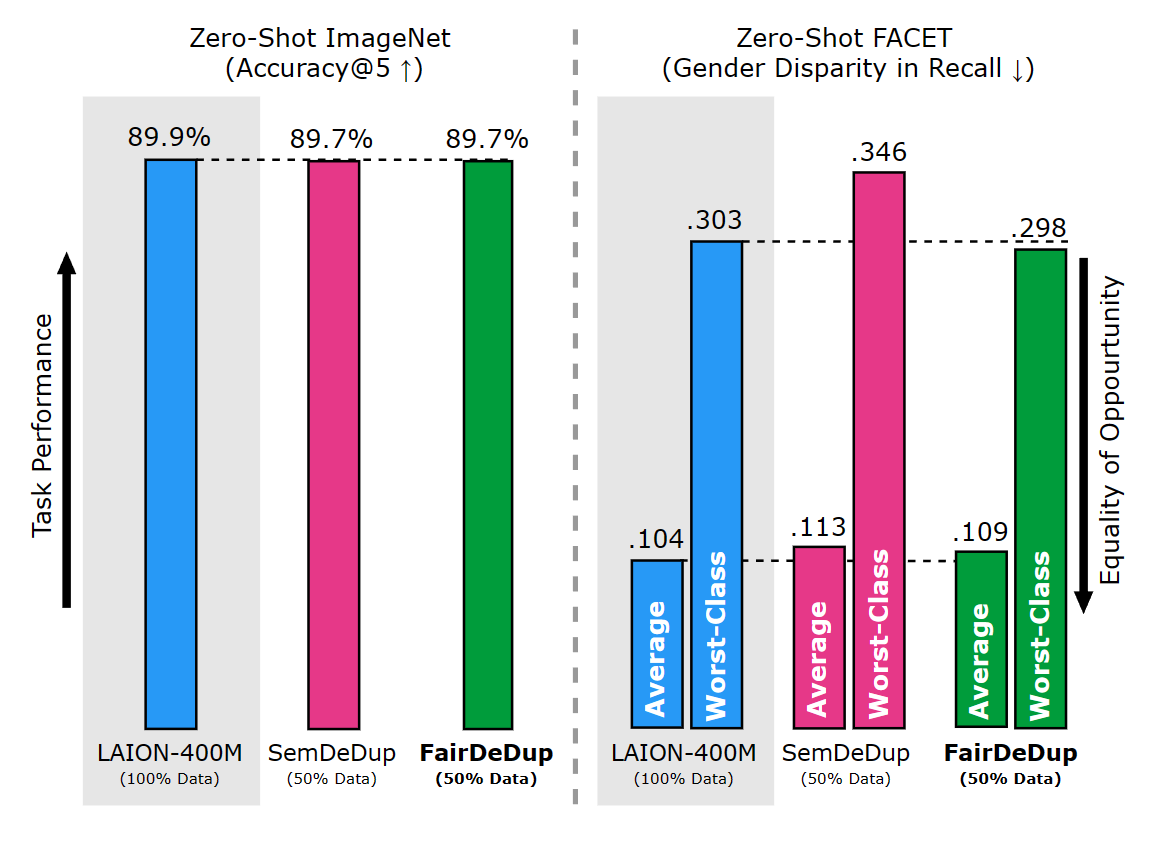 FairDeDup: Detecting and Mitigating Vision-Language Fairness Disparities in Semantic Dataset DeduplicationComputer Vision and Patern Recognition, Jun 2024
FairDeDup: Detecting and Mitigating Vision-Language Fairness Disparities in Semantic Dataset DeduplicationComputer Vision and Patern Recognition, Jun 2024Recent dataset deduplication techniques have demonstrated that content-aware dataset pruning can dramatically reduce the cost of training Vision-Language Pretrained (VLP) models without significant performance losses compared to training on the original dataset. These results have been based on pruning commonly used image-caption datasets collected from the web – datasets that are known to harbor harmful social biases that may then be codified in trained models. In this work, we evaluate how deduplication affects the prevalence of these biases in the resulting trained models and introduce an easy-to-implement modification to the recent SemDeDup algorithm that can reduce the negative effects that we observe. When examining CLIP-style models trained on deduplicated variants of LAION-400M, we find our proposed FairDeDup algorithm consistently leads to improved fairness metrics over SemDeDup on the FairFace and FACET datasets while maintaining zero-shot performance on CLIP benchmarks.
@article{slyman2024fairdedup, author = {Slyman, Eric and Lee, Stefan and Cohen, Scott and Kafle, Kushal}, title = {FairDeDup: Detecting and Mitigating Vision-Language Fairness Disparities in Semantic Dataset Deduplication}, journal = {Computer Vision and Patern Recognition}, month = jun, year = {2024}, } -
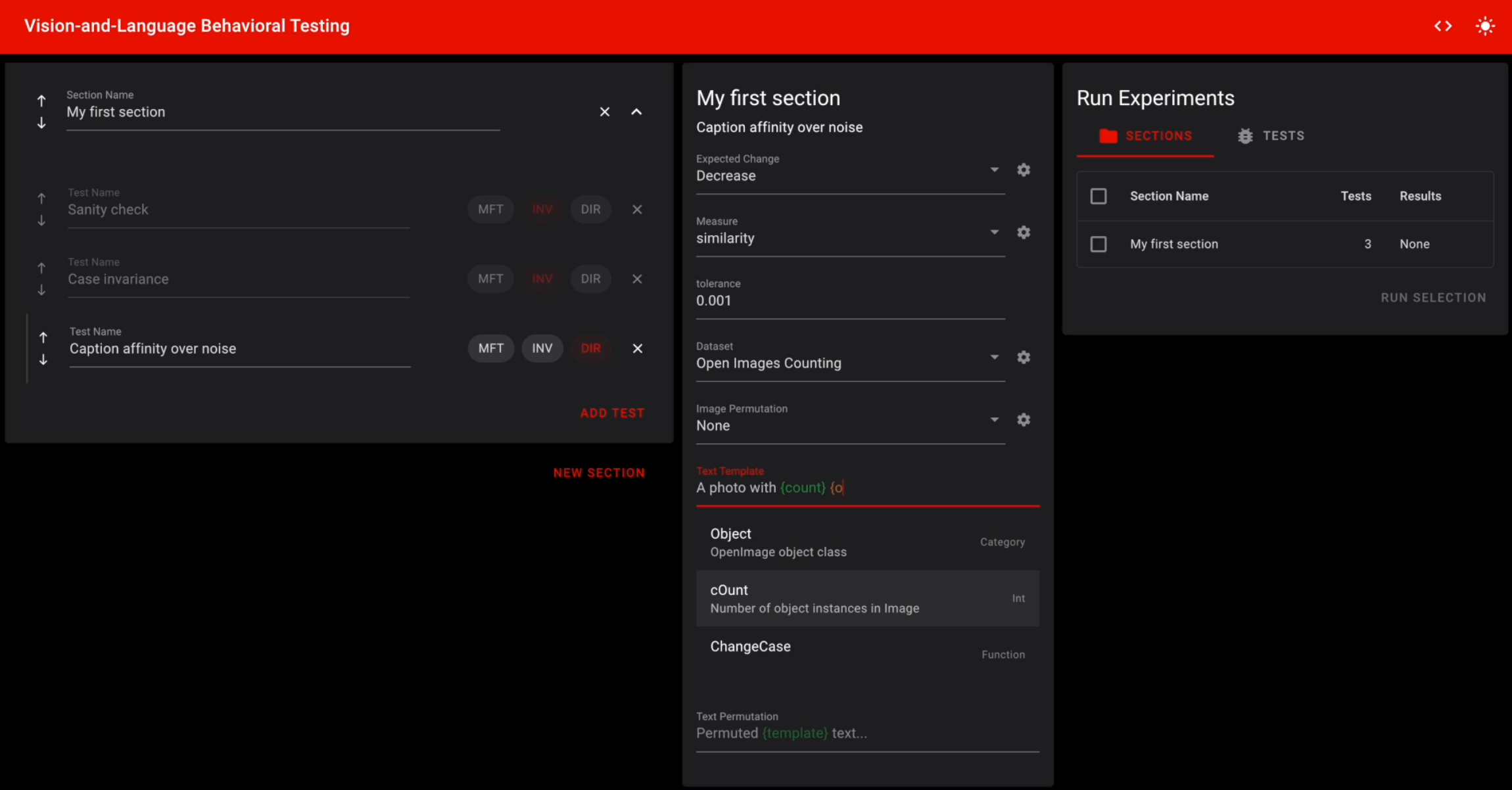 VALET: Vision-And-LanguagE Testing with Reusable ComponentsEric Slyman, Kushal Kafle, and Scott CohenNeurIPS Queer in AI Workshop, Dec 2023
VALET: Vision-And-LanguagE Testing with Reusable ComponentsEric Slyman, Kushal Kafle, and Scott CohenNeurIPS Queer in AI Workshop, Dec 2023Vision-and-Language (ViL) modeling advancements have resulted in significant improvements to aggregate metric performance on a variety of tasks. However, this evaluation may not accurately reflect a model’s capability to behave as intended by its creator, or according to the expectations of an end-user. Behavioral testing and sensemaking methods have been identified as effective for surfacing these errors in ViL models, but are limited in practice by their ability to scale to many examples and involved engineering requirements. In order to be practical for ViL tasks and suitable for organizational-level testing, these methods must scale to large sample sizes without requiring costly or repetitive engineering efforts for each individual test case. To address these challenges, we propose VALET, a system designed to rapidly develop scalable behavioral tests for ViL models that offers a high-level interface for non-technical users to perform testing that is supported by a modular system of interoperable components enabling expert users to extend and share testing environments more easily. We present a case study using VALET to evaluate a language-guided model’s capability to count in zero-shot image classification.
@article{slyman2023valet, author = {Slyman, Eric and Kafle, Kushal and Cohen, Scott}, title = {VALET: Vision-And-LanguagE Testing with Reusable Components}, journal = {NeurIPS Queer in AI Workshop}, month = dec, year = {2023}, } -
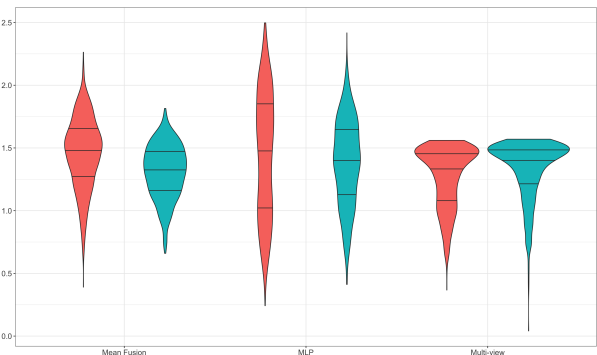 On the Behavior of Audio-Visual Fusion Architectures in Identity Verificaiton TasksDaniel Claborne, Eric Slyman, and Karl PazdernikarXiv preprint, Nov 2023
On the Behavior of Audio-Visual Fusion Architectures in Identity Verificaiton TasksDaniel Claborne, Eric Slyman, and Karl PazdernikarXiv preprint, Nov 2023We train an identity verification architecture and evaluate modifications to the part of the model that combines audio and visual representations – including in scenarios where one input is missing in either of two examples to be compared. We report results on the Voxceleb1-E test set that suggest averaging the output embeddings improves error rate in the full-modality setting and when a single modality is missing, and makes more complete use of the embedding space than systems which use shared layers and discuss possible reasons for this behavior.
@article{claborne2023behavior, author = {Claborne, Daniel and Slyman, Eric and Pazdernik, Karl}, title = {On the Behavior of Audio-Visual Fusion Architectures in Identity Verificaiton Tasks}, journal = {arXiv preprint}, month = nov, year = {2023}, } -
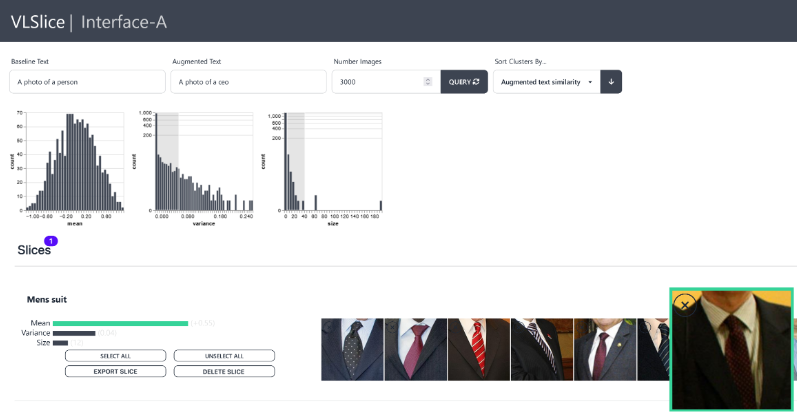 VLSlice: Interactive Vision-and-Language Slice DiscoveryEric Slyman, Minsuk Kahng, and Stefan LeeInternational Conference on Computer Vision, Oct 2023
VLSlice: Interactive Vision-and-Language Slice DiscoveryEric Slyman, Minsuk Kahng, and Stefan LeeInternational Conference on Computer Vision, Oct 2023Recent work in vision-and-language demonstrates that large-scale pretraining can learn generalizable models that are efficiently transferable to downstream tasks. While this may improve dataset-scale aggregate metrics, analyzing performance around hand-crafted subgroups targeting specific bias dimensions reveals systemic undesirable behaviors. However, this subgroup analysis is frequently stalled by annotation efforts, which require extensive time and resources to collect the necessary data. Prior art attempts to automatically discover subgroups to circumvent these constraints but typically leverages model behavior on existing task-specific annotations and rapidly degrades on more complex inputs beyond "tabular" data, none of which study vision-and-language models. This paper presents VLSlice, an interactive system enabling user-guided discovery of coherent representation-level subgroups with consistent visiolinguistic behavior, denoted as vision-and-language slices, from unlabeled image sets. We show that VLSlice enables users to quickly generate diverse high-coherency slices in a user study (n=22) and release the tool publicly.
@article{slyman2023vlslice, author = {Slyman, Eric and Kahng, Minsuk and Lee, Stefan}, title = {VLSlice: Interactive Vision-and-Language Slice Discovery}, journal = {International Conference on Computer Vision}, month = oct, year = {2023}, pages = {15291-15301}, } -
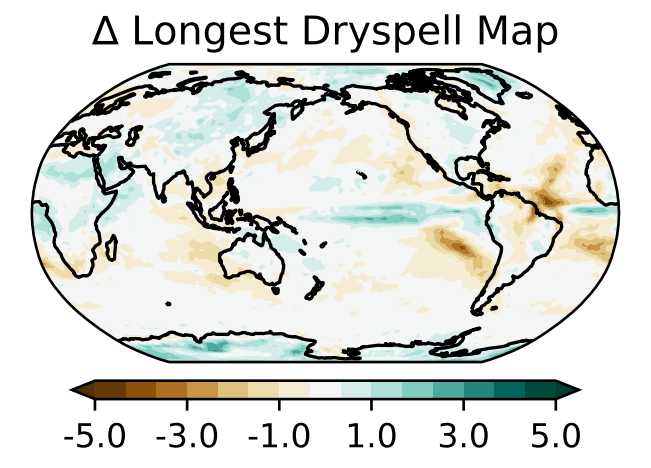 Conditional Emulation of Global Precipitation With Generative Adversarial NetworksICLR Workshop on AI for Earth and Space Science, Apr 2022
Conditional Emulation of Global Precipitation With Generative Adversarial NetworksICLR Workshop on AI for Earth and Space Science, Apr 2022Climate models encode our knowledge of the Earth system, enabling research on the earth’s future climate under alternative assumptions of how human-driven climate forcings, especially greenhouse gas emissions, will evolve. One important use of climate models is to estimate the impacts of climate change on natural and societal systems under these different possible futures. Unfortunately, running many simulations on existing models is extremely computationally expensive. These computational demands are particularly problematic for characterizing extreme events, which are rare and thus demand numerous simulations in order to precisely estimate the relevant climate statistics. In this paper we propose an approach to generating realistic global precipitation requiring orders of magnitude less computation, using a conditional generative adversarial network (GAN) as an emulator of an Earth System Model (ESM). Specifically, we present a GAN that emulates daily precipitation output from a fully coupled ESM, conditioned on monthly mean values. The GAN is trained to produce spatio-temporal samples: 28 days of precipitation in a 92x144 regular grid discretizing the globe. We evaluate the generator by comparing generated and real distributions of precipitation metrics including average precipitation, average fraction of dry days, average dry spell length, and average precipitation above the 90th percentile, finding the generated samples to closely match those of real data, even when conditioned on climate scenarios never seen during training.
@article{ayala2022conditional, title = {Conditional Emulation of Global Precipitation With Generative Adversarial Networks}, author = {Ayala, Alex and Drazic, Chris and Bassetti, Seth and Slyman, Eric and Nieva, Brenna and Wolters, Piper and Bittner, Kyle and Tebaldi, Claudia and Kravitz, Ben and Hutchinson, Brian}, journal = {ICLR Workshop on AI for Earth and Space Science}, month = apr, year = {2022}, } -
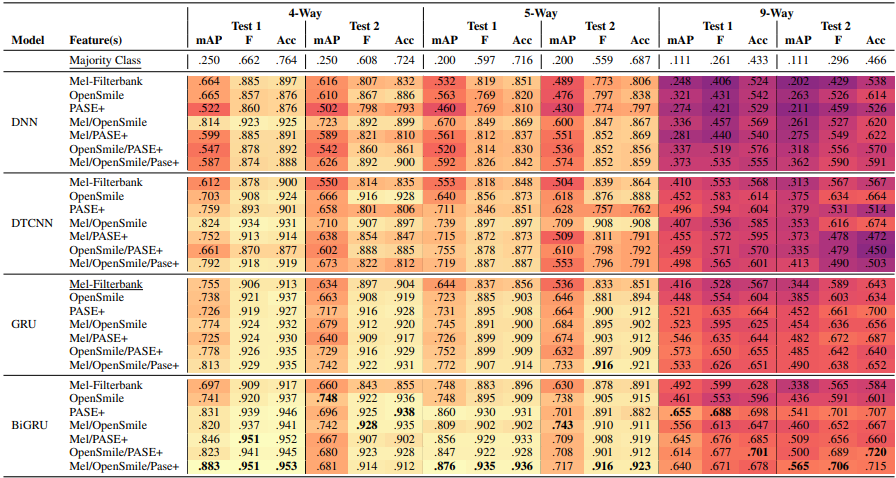 Fine-Grained Classroom Activity Detection from Audio with Neural NetworksEric Slyman, Chris Daw, Morgan Skrabut, Ana Usenko, and Brian HutchinsonAAAI Workshop on AI for Education, Feb 2022
Fine-Grained Classroom Activity Detection from Audio with Neural NetworksEric Slyman, Chris Daw, Morgan Skrabut, Ana Usenko, and Brian HutchinsonAAAI Workshop on AI for Education, Feb 2022Instructors are increasingly incorporating student-centered learning techniques in their classrooms to improve learning outcomes. In addition to lecture, these class sessions involve forms of individual and group work, and greater rates of student-instructor interaction. Quantifying classroom activity is a key element of accelerating the evaluation and refinement of innovative teaching practices, but manual annotation does not scale. In this manuscript, we present advances to the young application area of automatic classroom activity detection from audio. Using a university classroom corpus with nine activity labels (e.g., "lecture," "group work," "student question"), we propose and evaluate deep fully connected, convolutional, and recurrent neural network architectures, comparing the performance of mel-filterbank, OpenSmile, and self-supervised acoustic features. We compare 9-way classification performance with 5-way and 4-way simplifications of the task and assess two types of generalization: (1) new class sessions from previously seen instructors, and (2) previously unseen instructors. We obtain strong results on the new fine-grained task and state-of-the-art on the 4-way task: our best model obtains frame-level error rates of 6.2%, 7.7% and 28.0% when generalizing to unseen instructors for the 4-way, 5-way, and 9-way classification tasks, respectively (relative reductions of 35.4%, 48.3% and 21.6% over a strong baseline). When estimating the aggregate time spent on classroom activities, our average root mean squared error is 1.64 minutes per class session, a 54.9% relative reduction over the baseline.
@article{slyman2022finegrained, title = {Fine-Grained Classroom Activity Detection from Audio with Neural Networks}, author = {Slyman, Eric and Daw, Chris and Skrabut, Morgan and Usenko, Ana and Hutchinson, Brian}, journal = {AAAI Workshop on AI for Education}, month = feb, year = {2022}, } -
 Conditioned Emulation of Global Climate Models With Generative Adversarial NetworksNOAA Workshop on Leveraging AI in Envrionmental Sciences, Sep 2021
Conditioned Emulation of Global Climate Models With Generative Adversarial NetworksNOAA Workshop on Leveraging AI in Envrionmental Sciences, Sep 2021Climate models encapsulate our best understanding of the Earth system, allowing research to be conducted on its future under alternative assumptions of how human-driven climate forces are going to evolve. An important application of climate models is to provide metrics of mean and extreme climate changes, particularly under these alternative future scenarios, as these quantities drive the impacts of climate on society and natural systems. Because of the need to explore a wide range of alternative scenarios and other sources of uncertainties in a computationally efficient manner, climate models can only take us so far, as they require significant computational resources, especially when attempting to characterize extreme events, which are rare and thus demand long and numerous simulations in order to accurately represent their changing statistics. Here we demonstrate the capabilities of a Generative Adversarial Network (GAN) emulating a climate model. Our GAN is trained to produce spatio-temporal samples of precipitation and temperature conditioned on spatial monthly averages. We condition our GAN on several climate scenarios and task the generator with producing new realizations. These realizations are then evaluated under several climate metrics (SDII, dryness measures, etc.). Our trained GANs can generate realizations at a vastly reduced computational expense, compared to large ensembles of climate models, which greatly aids in estimating the statistics of extreme events.
@article{ayala21conditioned, title = {Conditioned Emulation of Global Climate Models With Generative Adversarial Networks}, author = {Ayala, Alex and Drazic, Chris and Slyman, Eric and Wolters, Piper and Nieva, Brenna and Hutchinson, Brian and Tebaldi, Claudia and Kravitz, Ben}, journal = {NOAA Workshop on Leveraging AI in Envrionmental Sciences}, month = sep, year = {2021}, }










{kind=link}
{kind=link}